Please note that rgdal will be retired by the end of 2023,
plan transition to sf/stars/terra functions using GDAL and PROJ
at your earliest convenience.
rgdal: version: 1.5-30, (SVN revision 1171)
Geospatial Data Abstraction Library extensions to R successfully loaded
Loaded GDAL runtime: GDAL 3.4.2, released 2022/03/08
Path to GDAL shared files: /Library/Frameworks/R.framework/Versions/4.2/Resources/library/rgdal/gdal
GDAL binary built with GEOS: FALSE
Loaded PROJ runtime: Rel. 8.2.1, January 1st, 2022, [PJ_VERSION: 821]
Path to PROJ shared files: /Library/Frameworks/R.framework/Versions/4.2/Resources/library/rgdal/proj
PROJ CDN enabled: FALSE
Linking to sp version:1.4-6
To mute warnings of possible GDAL/OSR exportToProj4() degradation,
use options("rgdal_show_exportToProj4_warnings"="none") before loading sp or rgdal.
To access larger datasets in this package, install the spDataLarge
package with: `install.packages('spDataLarge',
repos='https://nowosad.github.io/drat/', type='source')`
Loading required package: sf
Linking to GEOS 3.10.2, GDAL 3.4.2, PROJ 8.2.1; sf_use_s2() is TRUE
Before we start any analysis, let us set the path to the directory where we are working. We can easily do that with setwd(). Please replace in the following line the path to the folder where you have placed this file and where the house_transactions folder with the data lives.
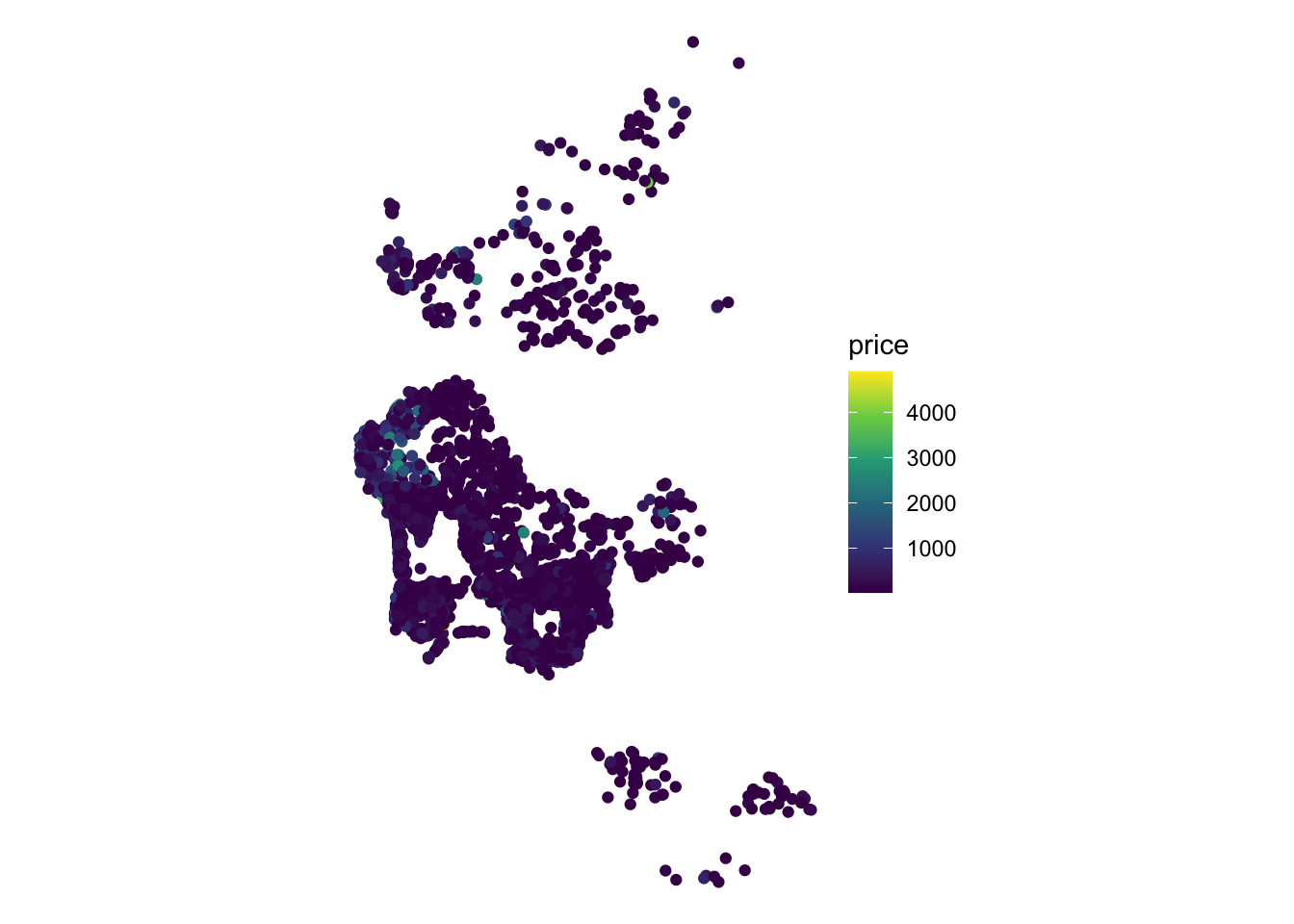
To explore ideas in spatial regression, we will the set of Airbnb properties for San Diego (US), borrowed from the “Geographic Data Science with Python” book (see here for more info on the dataset source). This covers the point location of properties advertised on the Airbnb website in the San Diego region.
For most of this chapter, we will be exploring determinants and strategies for modelling the price of a property advertised in AirBnb. To get a first taste of what this means, we can create a plot of prices within the area of San Diego:
Before we discuss how to explicitly include space into the linear regression framework, let us show how basic regression can be carried out in R, and how you can interpret the results. By no means is this a formal and complete introduction to regression so, if that is what you are looking for, the first part of Gelman and Hill (2006), in particular chapters 3 and 4, are excellent places to check out.
The core idea of linear regression is to explain the variation in a given (dependent) variable as a linear function of a series of other (explanatory) variables. For example, in our case, we may want to express/explain the price of a property advertised on AirBnb as a function of some of its characteristics, such as the number of people it accommodates, and how many bathrooms, bedrooms and beds it features. At the individual level, we can express this as:
where \(P_i\) is the price of house \(i\), \(Acc_i\), \(Bath_i\), \(Bedr_i\) and \(Beds_i\) are the count of people it accommodates, bathrooms, bedrooms and beds that house \(i\) has, respectively. The parameters \(\beta_{1,2, 3, 4}\) give us information about in which way and to what extent each variable is related to the price, and \(\alpha\), the constant term, is the average house price when all the other variables are zero. The term \(\epsilon_i\) is usually referred to as the “error” and captures elements that influence the price of a house but are not accounted for explicitly. We can also express this relation in matrix form, excluding subindices for \(i\) as:
\[
\log(P) = \alpha + \beta_1 Acc + \beta_2 Bath + \beta_3 Bedr + \beta_4 Beds + \epsilon
\] where each term can be interpreted in terms of vectors instead of scalars (wit the exception of the parameters \((\alpha, \beta_{1, 2, 3, 4})\), which are scalars). Note we are using the logarithm of the price, since this allows us to interpret the coefficients as roughly the percentage change induced by a unit increase in the explanatory variable of the estimate.
Remember a regression can be seen as a multivariate extension of bivariate correlations. Indeed, one way to interpret the \(\beta_k\) coefficients in the equation above is as the degree of correlation between the explanatory variable \(k\) and the dependent variable, keeping all the other explanatory variables constant. When you calculate simple bivariate correlations, the coefficient of a variable is picking up the correlation between the variables, but it is also subsuming into it variation associated with other correlated variables –also called confounding factors1. Regression allows you to isolate the distinct effect that a single variable has on the dependent one, once we control for those other variables.
1EXAMPLE Assume that new houses tend to be built more often in areas with low deprivation. If that is the case, then \(NEW\) and \(IMD\) will be correlated with each other (as well as with the price of a house, as we are hypothesizing in this case). If we calculate a simple correlation between \(P\) and \(IMD\), the coefficient will represent the degree of association between both variables, but it will also include some of the association between \(IMD\) and \(NEW\). That is, part of the obtained correlation coefficient will be due not to the fact that higher prices tend to be found in areas with low IMD, but to the fact that new houses tend to be more expensive. This is because (in this example) new houses tend to be built in areas with low deprivation and simple bivariate correlation cannot account for that.
Practically speaking, running linear regressions in R is straightforward. For example, to fit the model specified in the equation above, we only need one line of code:
We use the command lm, for linear model, and specify the equation we want to fit using a string that relates the dependent variable (the log of the price, log_price) with a set of explanatory ones (accommodates, bathrooms, bedrooms, beds) by using a tilde ~ that is akin to the \(=\) symbol in the mathematical equation above. Since we are using names of variables that are stored in a table, we need to pass the table object (db) as well.
In order to inspect the results of the model, the quickest way is to call summary:
Call:
lm(formula = "log_price ~ accommodates + bathrooms + bedrooms + beds",
data = db)
Residuals:
Min 1Q Median 3Q Max
-2.8486 -0.3234 -0.0095 0.3023 3.3975
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 4.018133 0.013947 288.10 <2e-16 ***
accommodates 0.176851 0.005323 33.23 <2e-16 ***
bathrooms 0.150981 0.012526 12.05 <2e-16 ***
bedrooms 0.111700 0.012537 8.91 <2e-16 ***
beds -0.076974 0.007927 -9.71 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.5366 on 6105 degrees of freedom
Multiple R-squared: 0.5583, Adjusted R-squared: 0.558
F-statistic: 1929 on 4 and 6105 DF, p-value: < 2.2e-16
A full detailed explanation of the output is beyond the scope of the chapter, but we will highlight the relevant bits for our main purpose. This is concentrated on the Coefficients section, which gives us the estimates for the \(\beta_k\) coefficients in our model. These estimates are the raw equivalent of the correlation coefficient between each explanatory variable and the dependent one, once the “polluting” effect of the other variables included in the model has been accounted for2. Results are as expected for the most part: houses tend to be significantly more expensive if they accommodate more people (an extra person increases the price by 17.7%, approximately), have more bathrooms (15.1%), or bedrooms (11.2%). Perhaps counter intuitively, an extra bed available seems to decrease the price by about -7.7%. However, keep in mind that this is the case, everything else equal. Hence, more beds per room and bathroom (ie. a more crowded house) is a bit cheaper.
2 Keep in mind that regression is no magic. We are only discounting the effect of other confounding factors that we include in the model, not of all potentially confounding factors.
6.4 Spatial regression: a (very) first dip
Spatial regression is about explicitly introducing space or geographical context into the statistical framework of a regression. Conceptually, we want to introduce space into our model whenever we think it plays an important role in the process we are interested in, or when space can act as a reasonable proxy for other factors we cannot but should include in our model. As an example of the former, we can imagine how houses at the seafront are probably more expensive than those in the second row, given their better views. To illustrate the latter, we can think of how the character of a neighborhood is important in determining the price of a house; however, it is very hard to identify and quantify “character” per se, although it might be easier to get at its spatial variation, hence a case of space as a proxy.
Spatial regression is a large field of development in the econometrics and statistics literature. In this brief introduction, we will consider two related but very different processes that give rise to spatial effects: spatial heterogeneity and spatial dependence. For more rigorous treatments of the topics introduced here, the reader is referred to Anselin (2003), Anselin and Rey (2014), and Gibbons, Overman, and Patacchini (2014).
6.5 Spatial dependence
As we have just discussed, SH is about effects of phenomena that are explicitly linked to geography and that hence cause spatial variation and clustering of values. This encompasses many of the kinds of spatial effects we may be interested in when we fit linear regressions. However, in other cases, our interest is on the effect of the spatial configuration of the observations, and the extent to which that has an effect on the outcome we are considering. For example, we might think that the price of a house not only depends on the number of bathrooms it has but, if we take number of bathrooms as a proxy for size and status, also whether it is surrounded by other houses with many bathrooms. This kind of spatial effect is fundamentally different from SH in that is it not related to inherent characteristics of the geography but relates to the characteristics of the observations in our dataset and, specially, to their spatial arrangement. We call this phenomenon by which the values of observations are related to each other through distance spatial dependence(Anselin 1988).
Spatial Weights
There are several ways to introduce spatial dependence in an econometric framework, with varying degrees of econometric sophistication (see Anselin 2003 for a good overview). Common to all of them however is the way space is formally encapsulated: through spatial weights matrices (\(W\))3 These are \(NxN\) matrices with zero diagonals and every \(w_{ij}\) cell with a value that represents the degree of spatial connectivity/interaction between observations \(i\) and \(j\). If they are not connected at all, \(w_{ij}=0\), otherwise \(w_{ij}>0\) and we call \(i\) and \(j\) neighbors. The exact value in the latter case depends on the criterium we use to define neighborhood relations. These matrices also tend to be row-standardized so the sum of each row equals to one.
3 If you need to refresh your knowledge on spatial weight matrices, check Block E of Arribas-Bel (2019); Chapter 4 of Rey, Arribas-Bel, and Wolf (forthcoming); or the Spatial Weights Section of Rowe (2022).
A related concept to spatial weight matrices is that of spatial lag. This is an operator that multiplies a given variable \(y\) by a spatial weight matrix:
\[
y_{lag} = W y
\]
If \(W\) is row-standardized, \(y_{lag}\) is effectively the average value of \(y\) in the neighborhood of each observation. The individual notation may help clarify this:
\[
y_{lag-i} = \displaystyle \sum_j w_{ij} y_j
\]
where \(y_{lag-i}\) is the spatial lag of variable \(y\) at location \(i\), and \(j\) sums over the entire dataset. If \(W\) is row-standardized, \(y_{lag-i}\) becomes an average of \(y\) weighted by the spatial criterium defined in \(W\).
Given that spatial weights matrices are not the focus of this tutorial, we will stick to a very simple case. Since we are dealing with points, we will use \(K\)-nn weights, which take the \(k\) nearest neighbors of each observation as neighbors and assign a value of one, assigning everyone else a zero. We will use \(k=50\) to get a good degree of variation and sensible results.
We can inspect the weights created by simply typing the name of the object:
hknn
Characteristics of weights list object:
Neighbour list object:
Number of regions: 6110
Number of nonzero links: 305500
Percentage nonzero weights: 0.8183306
Average number of links: 50
Non-symmetric neighbours list
Weights style: W
Weights constants summary:
n nn S0 S1 S2
W 6110 37332100 6110 220.5032 24924.44
Exogenous spatial effects
Let us come back to the house price example we have been working with. So far, we have hypothesized that the price of an AirBnb property in San Diego can be explained using information about its own characteristics, and the neighbourhood it belongs to. However, we can hypothesise that the price of a house is also affected by the characteristics of the houses surrounding it. Considering it as a proxy for larger and more luxurious houses, we will use the number of bathrooms of neighboring houses as an additional explanatory variable. This represents the most straightforward way to introduce spatial dependence in a regression, by considering not only a given explanatory variable, but also its spatial lag.
In our example case, in addition to including the number of bathrooms of the property, we will include its spatial lag. In other words, we will be saying that it is not only the number of bathrooms in a house but also that of the surrounding properties that helps explain the final price at which a house is advertised for. Mathematically, this implies estimating the following model:
As we can see, the lag is not only significative and positive, but its effect seems to be even larger that that of the property itself. Taken literally, this implies that the average number of bathrooms in AirBnb’s nearby has a larger effect on the final price of a given AirBnb than its own number of bathrooms. There are several ways to interpret this. One is that, if we take the spatial lag of bathrooms, as we said above, to be a proxy for the types of houses surrounding a property, this is probably a better predictor of how wealthy an area is than the number of bathrooms of a single property, which is more variable. If we also assume that the area where an AirBnb is located has a bigger effect on price than the number of bathrooms, we can start seeing an answer to the apparent puzzle.
A note on more advanced spatial regression
Introducing a spatial lag of an explanatory variable, as we have just seen, is the most straightforward way of incorporating the notion of spatial dependence in a linear regression framework. It does not require additional changes, it can be estimated with OLS, and the interpretation is rather similar to interpreting non-spatial variables. The field of spatial econometrics however is a much broader one and has produced over the last decades many techniques to deal with spatial effects and spatial dependence in different ways. Although this might be an over simplification, one can say that most of such efforts for the case of a single cross-section are focused on two main variations: the spatial lag and the spatial error model. Both are similar to the case we have seen in that they are based on the introduction of a spatial lag, but they differ in the component of the model they modify and affect.
The spatial lag model introduces a spatial lag of the dependent variable. In the example we have covered, this would translate into:
Again, although similar, one can show this specification violates the assumptions about the error term in a classical OLS model.
Both the spatial lag and error model violate some of the assumptions on which OLS relies and thus render the technique unusable. Much of the efforts have thus focused on coming up with alternative methodologies that allow unbiased, robust, and efficient estimation of such models. A survey of those is beyond the scope of this note, but the interested reader is referred to Anselin (1988), Anselin (2003), and Anselin and Rey (2014) for further reference.
6.6 Predicting house prices
So far, we have seen how to exploit the output of a regression model to evaluate the role different variables play in explaining another one of interest. However, once fit, a model can also be used to obtain predictions of the dependent variable given a new set of values for the explanatory variables. We will finish this session by dipping our toes in predicting with linear models.
The core idea is that once you have estimates for the way in which the explanatory variables can be combined to explain the dependent one, you can plug new values on the explanatory side of the model and combine them following the model estimates to obtain predictions. In the example we have worked with, you can imagine this application would be useful to obtain valuations of a house, given we know its characteristics.
Conceptually, predicting in linear regression models involves using the estimates of the parameters to obtain a value for the dependent variable:
\[
\bar{\log(P_i)} = \bar{\alpha} + \bar{\beta_1} Acc_i^* + \bar{\beta_2 Bath_i^*} + \bar{\beta_3} Bedr_i^* + \bar{\beta_4} Beds_i^*
\] where \(\bar{\log{P_i}}\) is our predicted value, and we include the \(\bar{}\) sign to note that it is our estimate obtained from fitting the model. We use the \(^*\) sign to note that those can be new values for the explanatory variables, not necessarily those used to fit the model.
Technically speaking, prediction in linear models is relatively streamlined in R. Suppose we are given data for a new house which is to be put on the AirBnb platform. We know it accommodates four people, and has two bedrooms, three beds, and one bathroom. We also know that the surrounding properties have, on average, 1.5 bathrooms. Let us record the data first:
Now remember we were using the log of the price as dependent variable. If we want to recover the actual price of the house, we need to take its exponent:
Fit a model that augments the baseline in 1. with the spatial lag of a variable you consider interesting. Motivate this choice. Note that to complete this, you will need to also generate a spatial weights matrix.
In each instance, provide a brief interpretation (no more thana few lines for each) that demonstrates your understanding of theunderlying concepts behind your approach.
Anselin, Luc. 1988. Spatial Econometrics: Methods and Models. Vol. 4. Springer Science & Business Media.
# Spatial dependenceThis chapter is based on the following references, which are good follow-up's on the topic:- [Chapter 11](https://geographicdata.science/book/notebooks/11_regression.html) of the GDS Book, by @reyABwolf.- [Session III](http://darribas.org/sdar_mini/notes/Class_03.html) of @arribas2014spatial. Check the "Related readings" section on the session page for more in-depth discussions.- @anselin2005spatial, freely available to download \[[`pdf`](https://dces.wisc.edu/wp-content/uploads/sites/128/2013/08/W14_Anselin2007.pdf)\].- The second part of this tutorial assumes you have reviewed [Block E](https://darribas.org/gds_course/content/bE/concepts_E.html) of @darribas_gds_course.## DependenciesWe will rely on the following libraries in this section, all of them included in @sec-dependencies:```{r}# Layoutlibrary(tufte)# For pretty tablelibrary(knitr)# For string parsinglibrary(stringr)# Spatial Data managementlibrary(rgdal)# Pretty graphicslibrary(ggplot2)# Pretty mapslibrary(ggmap)# For all your interpolation needslibrary(gstat)# For data manipulationlibrary(dplyr)# Spatial regressionlibrary(spdep)```Before we start any analysis, let us set the path to the directory where we are working. We can easily do that with `setwd()`. Please replace in the following line the path to the folder where you have placed this file and where the `house_transactions` folder with the data lives.```{r}setwd('.')```## DataTo explore ideas in spatial regression, we will the set of Airbnb properties for San Diego (US), borrowed from the "Geographic Data Science with Python" book (see [here](https://geographicdata.science/book/data/airbnb/regression_cleaning.html) for more info on the dataset source). This covers the point location of properties advertised on the Airbnb website in the San Diego region.Let us load the data:```{r}db <-st_read('data/abb_sd/regression_db.geojson')```The table contains the followig variables:```{r}names(db)```For most of this chapter, we will be exploring determinants and strategies for modelling the price of a property advertised in AirBnb. To get a first taste of what this means, we can create a plot of prices within the area of San Diego:```{r}db %>%ggplot(aes(color = price)) +geom_sf() +scale_color_viridis_c() +theme_void()```## Non-spatial regression, a refreshBefore we discuss how to explicitly include space into the linear regression framework, let us show how basic regression can be carried out in R, and how you can interpret the results. By no means is this a formal and complete introduction to regression so, if that is what you are looking for, the first part of @gelman2006data, in particular chapters 3 and 4, are excellent places to check out.The core idea of linear regression is to explain the variation in a given (*dependent*) variable as a linear function of a series of other (*explanatory*) variables. For example, in our case, we may want to express/explain the price of a property advertised on AirBnb as a function of some of its characteristics, such as the number of people it accommodates, and how many bathrooms, bedrooms and beds it features. At the individual level, we can express this as:$$\log(P_i) = \alpha + \beta_1 Acc_i + \beta_2 Bath_i + \beta_3 Bedr_i + \beta_4 Beds_i + \epsilon_i$$where $P_i$ is the price of house $i$, $Acc_i$, $Bath_i$, $Bedr_i$ and $Beds_i$ are the count of people it accommodates, bathrooms, bedrooms and beds that house $i$ has, respectively. The parameters $\beta_{1,2, 3, 4}$ give us information about in which way and to what extent each variable is related to the price, and $\alpha$, the constant term, is the average house price when all the other variables are zero. The term $\epsilon_i$ is usually referred to as the "error" and captures elements that influence the price of a house but are not accounted for explicitly. We can also express this relation in matrix form, excluding subindices for $i$ as:$$\log(P) = \alpha + \beta_1 Acc + \beta_2 Bath + \beta_3 Bedr + \beta_4 Beds + \epsilon$$ where each term can be interpreted in terms of vectors instead of scalars (wit the exception of the parameters $(\alpha, \beta_{1, 2, 3, 4})$, which *are* scalars). Note we are using the logarithm of the price, since this allows us to interpret the coefficients as roughly the percentage change induced by a unit increase in the explanatory variable of the estimate.Remember a regression can be seen as a multivariate extension of bivariate correlations. Indeed, one way to interpret the $\beta_k$ coefficients in the equation above is as the degree of correlation between the explanatory variable $k$ and the dependent variable, *keeping all the other explanatory variables constant*. When you calculate simple bivariate correlations, the coefficient of a variable is picking up the correlation between the variables, but it is also subsuming into it variation associated with other correlated variables --also called confounding factors[^06-spatial-econometrics-1]. Regression allows you to isolate the distinct effect that a single variable has on the dependent one, once we *control* for those other variables.[^06-spatial-econometrics-1]: **EXAMPLE** Assume that new houses tend to be built more often in areas with low deprivation. If that is the case, then $NEW$ and $IMD$ will be correlated with each other (as well as with the price of a house, as we are hypothesizing in this case). If we calculate a simple correlation between $P$ and $IMD$, the coefficient will represent the degree of association between both variables, but it will also include some of the association between $IMD$ and $NEW$. That is, part of the obtained correlation coefficient will be due not to the fact that higher prices tend to be found in areas with low IMD, but to the fact that new houses tend to be more expensive. This is because (in this example) new houses tend to be built in areas with low deprivation and simple bivariate correlation cannot account for that.Practically speaking, running linear regressions in `R` is straightforward. For example, to fit the model specified in the equation above, we only need one line of code:```{r}m1 <-lm('log_price ~ accommodates + bathrooms + bedrooms + beds', db)```We use the command `lm`, for linear model, and specify the equation we want to fit using a string that relates the dependent variable (the log of the price, `log_price`) with a set of explanatory ones (`accommodates`, `bathrooms`, `bedrooms`, `beds`) by using a tilde `~` that is akin to the $=$ symbol in the mathematical equation above. Since we are using names of variables that are stored in a table, we need to pass the table object (`db`) as well.In order to inspect the results of the model, the quickest way is to call `summary`:```{r}summary(m1)```A full detailed explanation of the output is beyond the scope of the chapter, but we will highlight the relevant bits for our main purpose. This is concentrated on the `Coefficients` section, which gives us the estimates for the $\beta_k$ coefficients in our model. These estimates are the raw equivalent of the correlation coefficient between each explanatory variable and the dependent one, once the "polluting" effect of the other variables included in the model has been accounted for[^06-spatial-econometrics-2]. Results are as expected for the most part: houses tend to be significantly more expensive if they accommodate more people (an extra person increases the price by `r round(m1$coefficients[["accommodates"]], 3) * 100`%, approximately), have more bathrooms (`r round(m1$coefficients[["bathrooms"]], 3) * 100`%), or bedrooms (`r round(m1$coefficients[["bedrooms"]], 3) * 100`%). Perhaps counter intuitively, an extra bed available seems to decrease the price by about `r round(m1$coefficients[["beds"]], 3) * 100`%. However, keep in mind that this is the case, *everything else equal*. Hence, more beds per room and bathroom (ie. a more crowded house) is a bit cheaper.[^06-spatial-econometrics-2]: Keep in mind that regression is no magic. We are only discounting the effect of other confounding factors that we include in the model, not of *all* potentially confounding factors.## Spatial regression: a (very) first dipSpatial regression is about *explicitly* introducing space or geographical context into the statistical framework of a regression. Conceptually, we want to introduce space into our model whenever we think it plays an important role in the process we are interested in, or when space can act as a reasonable proxy for other factors we cannot but should include in our model. As an example of the former, we can imagine how houses at the seafront are probably more expensive than those in the second row, given their better views. To illustrate the latter, we can think of how the character of a neighborhood is important in determining the price of a house; however, it is very hard to identify and quantify "character" per se, although it might be easier to get at its spatial variation, hence a case of space as a proxy.Spatial regression is a large field of development in the econometrics and statistics literature. In this brief introduction, we will consider two related but very different processes that give rise to spatial effects: spatial heterogeneity and spatial dependence. For more rigorous treatments of the topics introduced here, the reader is referred to @anselin2003spatial, @anselin2014modern, and @gibbons2014spatial.## Spatial dependenceAs we have just discussed, SH is about effects of phenomena that are *explicitly linked* to geography and that hence cause spatial variation and clustering of values. This encompasses many of the kinds of spatial effects we may be interested in when we fit linear regressions. However, in other cases, our interest is on the effect of the *spatial configuration* of the observations, and the extent to which that has an effect on the outcome we are considering. For example, we might think that the price of a house not only depends on the number of bathrooms it has but, if we take number of bathrooms as a proxy for size and status, also whether it is surrounded by other houses with many bathrooms. This kind of spatial effect is fundamentally different from SH in that is it not related to inherent characteristics of the geography but relates to the characteristics of the observations in our dataset and, specially, to their spatial arrangement. We call this phenomenon by which the values of observations are related to each other through distance *spatial dependence* [@anselin1988spatial].**Spatial Weights**There are several ways to introduce spatial dependence in an econometric framework, with varying degrees of econometric sophistication [see @anselin2003spatial for a good overview]. Common to all of them however is the way space is formally encapsulated: through *spatial weights matrices (*$W$)[^06-spatial-econometrics-3] These are $NxN$ matrices with zero diagonals and every $w_{ij}$ cell with a value that represents the degree of spatial connectivity/interaction between observations $i$ and $j$. If they are not connected at all, $w_{ij}=0$, otherwise $w_{ij}>0$ and we call $i$ and $j$ neighbors. The exact value in the latter case depends on the criterium we use to define neighborhood relations. These matrices also tend to be row-standardized so the sum of each row equals to one.[^06-spatial-econometrics-3]: If you need to refresh your knowledge on spatial weight matrices, check [Block E](https://darribas.org/gds_course/content/bE/concepts_E.html) of @darribas_gds_course; [Chapter 4](https://geographicdata.science/book/notebooks/04_spatial_weights.html) of @reyABwolf; or the [Spatial Weights](https://fcorowe.github.io/intro-gds/03-spatial_weights.html) Section of @rowe2022a.A related concept to spatial weight matrices is that of *spatial lag*. This is an operator that multiplies a given variable $y$ by a spatial weight matrix:$$y_{lag} = W y$$If $W$ is row-standardized, $y_{lag}$ is effectively the average value of $y$ in the neighborhood of each observation. The individual notation may help clarify this:$$y_{lag-i} = \displaystyle \sum_j w_{ij} y_j$$where $y_{lag-i}$ is the spatial lag of variable $y$ at location $i$, and $j$ sums over the entire dataset. If $W$ is row-standardized, $y_{lag-i}$ becomes an average of $y$ weighted by the spatial criterium defined in $W$.Given that spatial weights matrices are not the focus of this tutorial, we will stick to a very simple case. Since we are dealing with points, we will use $K$-nn weights, which take the $k$ nearest neighbors of each observation as neighbors and assign a value of one, assigning everyone else a zero. We will use $k=50$ to get a good degree of variation and sensible results.```{r}# Create knn list of each househnn <- db %>%st_coordinates() %>%as.matrix() %>%knearneigh(k =50)# Create nb objecthnb <-knn2nb(hnn)# Create spatial weights matrix (note it row-standardizes by default)hknn <-nb2listw(hnb)```We can inspect the weights created by simply typing the name of the object:```{r}hknn```**Exogenous spatial effects**Let us come back to the house price example we have been working with. So far, we have hypothesized that the price of an AirBnb property in San Diego can be explained using information about its own characteristics, and the neighbourhood it belongs to. However, we can hypothesise that the price of a house is also affected by the characteristics of the houses surrounding it. Considering it as a proxy for larger and more luxurious houses, we will use the number of bathrooms of neighboring houses as an additional explanatory variable. This represents the most straightforward way to introduce spatial dependence in a regression, by considering not only a given explanatory variable, but also its spatial lag.In our example case, in addition to including the number of bathrooms of the property, we will include its spatial lag. In other words, we will be saying that it is not only the number of bathrooms in a house but also that of the surrounding properties that helps explain the final price at which a house is advertised for. Mathematically, this implies estimating the following model:$$\log(P_i) = \alpha + \beta_1 Acc_i + \beta_2 Bath_i + \beta_3 Bedr_i + \beta_4 Beds_i+ \beta_5 Bath_{lag-i} + \epsilon_i$$Let us first compute the spatial lag of `bathrooms`:```{r}db$w_bathrooms <-lag.listw(hknn, db$bathrooms)```And then we can include it in our previous specification. Note that we apply the log to the lag, not the reverse:```{r}m5 <-lm('log_price ~ accommodates + bedrooms + beds + bathrooms + w_bathrooms', db)summary(m5)```As we can see, the lag is not only significative and positive, but its effect seems to be even larger that that of the property itself. Taken literally, this implies that the average number of bathrooms in AirBnb's nearby has a larger effect on the final price of a given AirBnb than its own number of bathrooms. There are several ways to interpret this. One is that, if we take the spatial lag of bathrooms, as we said above, to be a proxy for the types of houses surrounding a property, this is probably a better predictor of how wealthy an area is than the number of bathrooms of a single property, which is more variable. If we also assume that the area where an AirBnb is located has a bigger effect on price than the number of bathrooms, we can start seeing an answer to the apparent puzzle.**A note on more advanced spatial regression**Introducing a spatial lag of an explanatory variable, as we have just seen, is the most straightforward way of incorporating the notion of spatial dependence in a linear regression framework. It does not require additional changes, it can be estimated with OLS, and the interpretation is rather similar to interpreting non-spatial variables. The field of spatial econometrics however is a much broader one and has produced over the last decades many techniques to deal with spatial effects and spatial dependence in different ways. Although this might be an over simplification, one can say that most of such efforts for the case of a single cross-section are focused on two main variations: the spatial lag and the spatial error model. Both are similar to the case we have seen in that they are based on the introduction of a spatial lag, but they differ in the component of the model they modify and affect.The spatial lag model introduces a spatial lag of the *dependent* variable. In the example we have covered, this would translate into:$$\log(P_i) = \alpha + \rho \log(P_i) + \beta_1 Acc_i + \beta_2 Bath_i + \beta_3 Bedr_i + \beta_4 Beds_i + \epsilon_i$$Although it might not seem very different from the previous equation, this model violates the exogeneity assumption, crucial for OLS to work.Equally, the spatial error model includes a spatial lag in the *error* term of the equation:$$\log(P_i) = \alpha + \beta_1 Acc_i + \beta_2 Bath_i + \beta_3 Bedr_i + \beta_4 Beds_i + u_i$$$$u_i = u_{lag-i} + \epsilon_i$$Again, although similar, one can show this specification violates the assumptions about the error term in a classical OLS model.Both the spatial lag and error model violate some of the assumptions on which OLS relies and thus render the technique unusable. Much of the efforts have thus focused on coming up with alternative methodologies that allow unbiased, robust, and efficient estimation of such models. A survey of those is beyond the scope of this note, but the interested reader is referred to @anselin1988spatial, @anselin2003spatial, and @anselin2014modern for further reference.## Predicting house pricesSo far, we have seen how to exploit the output of a regression model to evaluate the role different variables play in explaining another one of interest. However, once fit, a model can also be used to obtain predictions of the dependent variable given a new set of values for the explanatory variables. We will finish this session by dipping our toes in predicting with linear models.The core idea is that once you have estimates for the way in which the explanatory variables can be combined to explain the dependent one, you can plug new values on the explanatory side of the model and combine them following the model estimates to obtain predictions. In the example we have worked with, you can imagine this application would be useful to obtain valuations of a house, given we know its characteristics.Conceptually, predicting in linear regression models involves using the estimates of the parameters to obtain a value for the dependent variable:$$\bar{\log(P_i)} = \bar{\alpha} + \bar{\beta_1} Acc_i^* + \bar{\beta_2 Bath_i^*} + \bar{\beta_3} Bedr_i^* + \bar{\beta_4} Beds_i^*$$ where $\bar{\log{P_i}}$ is our predicted value, and we include the $\bar{}$ sign to note that it is our estimate obtained from fitting the model. We use the $^*$ sign to note that those can be new values for the explanatory variables, not necessarily those used to fit the model.Technically speaking, prediction in linear models is relatively streamlined in R. Suppose we are given data for a new house which is to be put on the AirBnb platform. We know it accommodates four people, and has two bedrooms, three beds, and one bathroom. We also know that the surrounding properties have, on average, 1.5 bathrooms. Let us record the data first:```{r}new.house <-data.frame(accommodates =4, bedrooms =2,beds =3,bathrooms =1,w_bathrooms =1.5)```To obtain the prediction for its price, we can use the `predict` method:```{r}new.price <-predict(m5, new.house)new.price```Now remember we were using the log of the price as dependent variable. If we want to recover the actual price of the house, we need to take its exponent:```{r}exp(new.price)```According to our model, the house would be worth \$`r exp(new.price)`.<!-- #region -->## QuestionsWe will be using again the Madrid AirBnb dataset: <!-- #endregion -->```{r}mad_abb <-st_read('./data/assignment_1_madrid/madrid_abb.gpkg')``````{r}colnames(mad_abb)```<!-- #region -->In addition to those we have already seen, the columns to use here are:- `neighbourhood`: a column with the name of the neighbourhood in which the property is locatedWith this at hand, answer the following questions:1. Fit a baseline model with only property characteristics explaining the log of price$$\log(P_i) = \alpha + \beta_1 Acc_i + \beta_2 Bath_i + \beta_3 Bedr_i + \beta_4 Beds_i + \epsilon_i$$2. Augment the model with fixed effects at the neighbourhood level$$\log(P_i) = \alpha_r + \beta_1 Acc_i + \beta_2 Bath_i + \beta_3 Bedr_i + \beta_4 Beds_i + \epsilon_i$$3. \[Optional\] Augment the model with spatial regimes at the neighbourhood level:$$\log(P_i) = \alpha_r + \beta_{r1} Acc_i + \beta_{r2} Bath_i + \beta_{r3} Bedr_i + \beta_{r4} Beds_i + \epsilon_{ri}$$4. Fit a model that augments the baseline in 1. with the spatial lag of a variable you consider interesting. Motivate this choice. Note that to complete this, you will need to also generate a spatial weights matrix.In each instance, provide a brief interpretation (no more thana few lines for each) that demonstrates your understanding of theunderlying concepts behind your approach. <!-- #endregion -->